Transportation Modelling using Software Development Principles
27 March 2017
It is a fact of life to transportation modellers that the models they employ are neither purely software or purely data but a rich hybrid of the two. The software portion of a model is generally developed around the data that is available and tends to grow organically as the requirements of that particular model change over time and as various practitioners are responsible for its maintenance.
However, this approach has significant drawbacks, two models within the same organisation will generally reimplement the same logical components with different design decisions. Code and data will change over time with no real means of seeing whether or not the current state is the result of decisions made at design time or in the heat of a particularly tight deadline project which utilised the model.
These are all problems that are largely solved in the software development industry, through:
- Version Control – systems such as SVN and git are almost universally used by software practitioners;
- Software Reuse – a practice which is encouraged in both formal training and community guidelines; and
- Automated Testing – a software development practice with recognised reliability benefits, exemplified in development methodologies such as Test Driven Development and Continuous Integration.
Many of these benefits can be realised by applying these techniques in the field of transport modelling. VLC are in a fairly unique position, having multiple models which share a common structure, which makes these techniques particularly appealing but the benefits can be attained by practitioners using models of all scales and complexity. In particular as the complexity of modelling increases with more complex interaction models, we believe that techniques such as these become essential.
Version Control
Software developers have long used so called Version Control Systems (VCS) to keep track of the myriad small changes to source code that occur over time. These systems have enjoyed significant evolution over the past 20 years, and the front runners in the current generation (Git, Mercurial, etc.) are leaps and bounds ahead of their forebears in terms of functionality and ease of use.
A particularly useful development is the move to online functionality, which increases the ability for teams to collaborate. GitHub is probably the most widely recognized web front end for any VCS and is our main choice for our version control needs. As an organisation we have both public and private repositories of code which we use for everything from our core modelling platform to occasional utilities and libraries that we think are worth sharing with the wider community.
While not every transport modelling group will have their own core modelling platform, a common thread in all transport models is that they are generally configured and run using text based scripts and data files. These scripts may be python, they may be a proprietary language of the modelling platform, the data may be csv, json or yaml. But no matter the language or format of the data, they can all benefit from storage within a modern VCS.
There are a number of benefits that can be obtained immediately by version controlling your key model inputs:
- Auditability: Each change to scripts/data is accompanied by a person (author) and a reason (commit message). This is invaluable when working out why a particular part of the model was set up in the manner it was.
- Working with a safety net: As a team working on a model, either in development or application, the ability to easily see what changes you have made as you progress can be invaluable. It is also liberating to be able to make as many changes as you like, break as many things as you like, experiment as you see fit… and still be able to easily roll back to a known good version of the model.
There are some other benefits that are only realised as teams change their overall workflow to better leverage the tooling. A great example of this is Github’s Pull Request workflow.
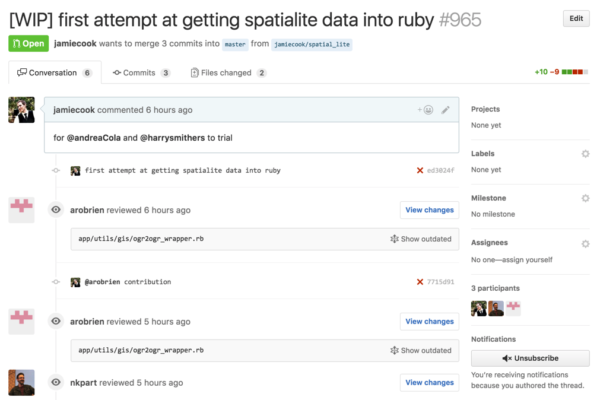
This feature allows a contributor to take a set of changes that they believe will be beneficial to a model and package them up and get feedback from other team members about those changes before those changes are “pulled” back into the main trunk. This is immensely powerful as it:
- allows mistakes (we all make them) to be spotted earlier, and
- knowledge to be shared amongst team members more freely. Allowing juniors to see the workflow employed by a senior team member and allowing senior members to provide feedback on juniors work.
Binary and GeoData
These benefits are most keenly felt when working with purely text based files as most of the tools surrounding VCS are built for working with text. Unfortunately there are large parts of our models that are not text based: spatial data, matrices and spreadsheets are just some of our favourites. But the fact that the tools are tailored for text doesn’t mean that our binary data can’t benefit from VCS as well. VLC use an internal Subversion server to handle large amounts of binary model data with all the benefits listed above. GitHub also provides large file storage support which makes it possible to store huge amounts of data (demand and skim matrices anyone?).
The one caveat to that is that while text based diff tools are commonly available that make it trivially easy to see exactly what was changed in a particular commit, they do not provide support for most binary file types.

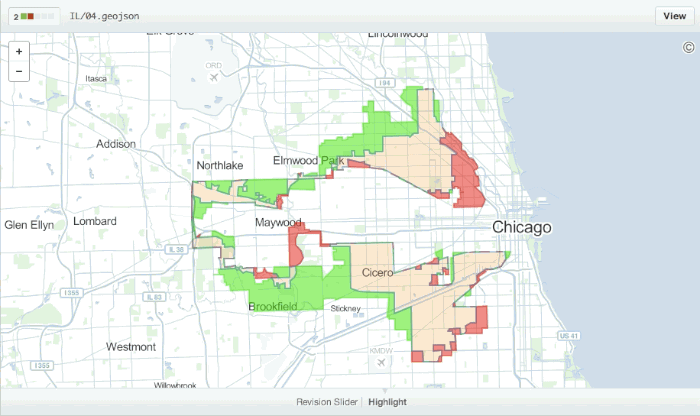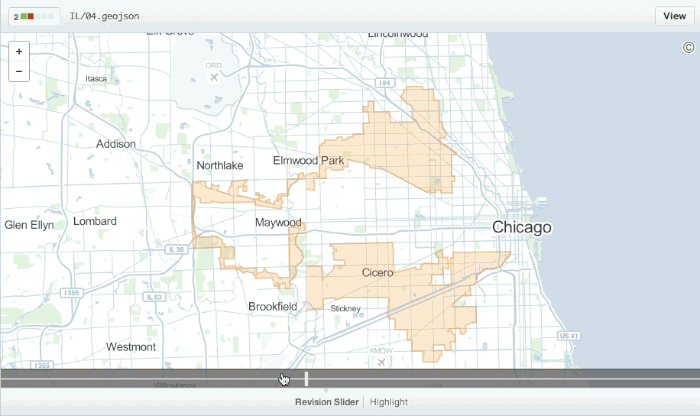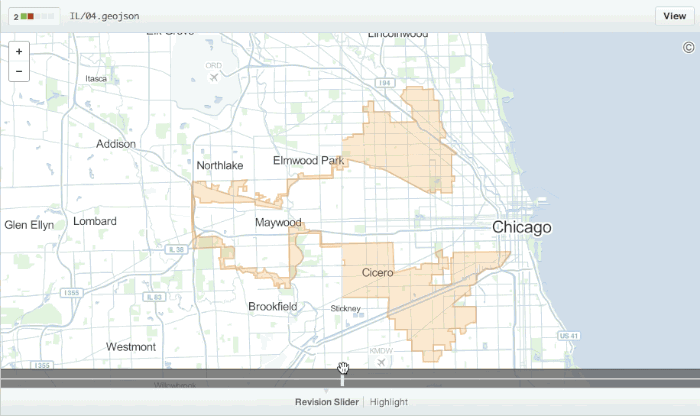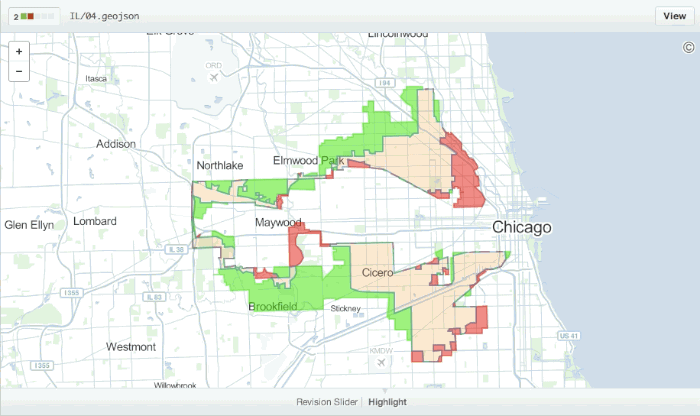
There are some exceptions to this however, Github have exceptional support for visualising changes in geospatial data stored in the geojson format: